大模型时代的新挑战 为何需要开发AI原生数据库与数据处理服务
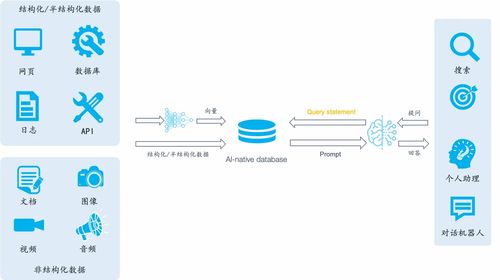
在人工智能的浪潮中,大模型已成为推动技术进步的核心引擎。随着模型规模和复杂度不断提升,传统数据处理和存储架构逐渐暴露出诸多瓶颈。这不仅催生了对高效计算资源的需求,也凸显了对新型数据库和数据服务的迫切性。本文将探讨大模型时代为何需要开发AI原生数据库和数据处理存储服务。
大模型依赖海量数据训练和推理,这些数据往往是非结构化或半结构化的,例如文本、图像、音频和视频。传统关系型数据库设计用于处理结构化数据,难以高效支持复杂的向量嵌入、图结构或时序数据。AI原生数据库通过优化存储引擎和查询接口,能够直接处理高维向量、张量等AI常用数据结构,显著提升数据处理效率。例如,向量数据库支持近似最近邻搜索,加速了推荐系统和语义检索任务。
大模型工作负载具有动态性和高并发性。训练阶段需要批量处理TB级数据,而推理阶段则需实时响应大量用户请求。传统数据库缺乏弹性伸缩和负载均衡能力,可能导致性能瓶颈。AI原生服务通常集成了分布式计算和存储框架,如基于云原生的架构,能够根据需求自动分配资源,确保低延迟和高可用性。这类服务还支持流式数据处理,满足实时AI应用如自动驾驶或智能客服的需求。
数据安全和隐私保护在大模型应用中至关重要。AI原生数据库可以嵌入隐私计算技术,如联邦学习或同态加密,在数据处理过程中保护用户数据不被泄露。它们提供细粒度的访问控制和审计功能,符合日益严格的法规要求,如GDPR或数据安全法。
开发AI原生数据库和服务有助于降低技术门槛。通过提供标准化的API和工具链,开发者可以专注于模型创新,而非底层基础设施的维护。例如,一些服务支持自动数据预处理和特征工程,简化了端到端的AI流水线。这不仅提高了生产力,还促进了AI技术的普及。
从生态角度来看,AI原生数据库和服务能够与机器学习框架(如TensorFlow或PyTorch)深度集成,形成协同效应。这推动了整个AI产业链的优化,从数据采集到模型部署,实现无缝衔接。
大模型时代对数据处理和存储提出了更高要求,开发AI原生数据库和服务不仅是技术演进的必然,也是推动AI应用落地的关键。它们通过优化数据结构支持、提升可扩展性、强化安全性与易用性,为人工智能的可持续发展奠定了坚实基础。随着AI技术的不断演进,我们有望看到更多创新的数据解决方案,进一步释放大模型的潜力。
如若转载,请注明出处:http://www.52animal.com/product/3.html
更新时间:2026-06-19 05:08:15